
| 일 | 월 | 화 | 수 | 목 | 금 | 토 |
|---|---|---|---|---|---|---|
| 1 | ||||||
| 2 | 3 | 4 | 5 | 6 | 7 | 8 |
| 9 | 10 | 11 | 12 | 13 | 14 | 15 |
| 16 | 17 | 18 | 19 | 20 | 21 | 22 |
| 23 | 24 | 25 | 26 | 27 | 28 | 29 |
| 30 |
- EC2
- MAC address
- Vision
- log
- JavaScript
- Network
- CSV
- CVAT
- Trino
- Python
- zookeeper
- aws s3
- kubeadm
- docker
- ip
- Kafka
- jvm
- Spring
- AWS
- Operating System
- grafana
- OS
- java
- helm
- PostgreSQL
- tcp
- kubernetes
- kubectl
- airflow
- Packet
- Today
- Total
JUST WRITE
[Trino] 너의 흔적을 기록하고 싶어 - 히스토리 데이터 영구 저장 본문

Trino 히스토리 데이터 영구 저장
사내에서 빅데이터 쿼리에 뛰어난 성능을 보여주는 Trino를 활용하고 있습니다.
빅데이터 쿼리뿐만 아니라 다른 데이터베이스의 데이터끼리 조인이 가능합니다.
현재 쿠버네티스 환경에 Trino를 구성해서 사용하고 있습니다.
다만 한 가지 문제가 있었습니다.
presto 기반의 쿼리 엔진이라 메모리를 사용해서 로그성 데이터가 남지 않았습니다.
따로 벡엔드 데이터베이스를 가지지 않습니다.
Trino에서 쿼리 한 이력을 확인하는데 큰 제약이 있습니다.
하지만 방법은 없는 것이 아닙니다.
Trino에서 쿼리 이력을 저장할 수 있도록 제공해 주는데 따로 설정이 필요합니다.
이번 포스팅에서는 Trino에서 쿼리 이력을 따로 저장하는 방법을 정리하도록 하겠습니다.
Trino WEB UI
이번 포스팅에서는 쿠버네티스에서 Trino를 구성하는 것을 정리하지 않겠습니다.
구성하는 방법은 아래 포스팅을 참고해 주시길 바랍니다.
Trino 한번 써보겠습니다(1) - Kubernetes에 Trino 설치
Trino 한번 써보겠습니다(1) RDB에서 데이터를 조회할 때 SQL를 통해 조회하였습니다. 데이터는 방대해져서 빅데이터가 생겼고, RDB뿐만 아니라 Storage의 종류도 다양해졌습니다. 데이터 조회는 다양
developnote-blog.tistory.com
helm를 통해 쿠버네티스에서 쉽게 구성이 가능합니다.
물론 운영시에는 리소스 관리, 쿼리 옵션 등 디테일한 설정들이 필요합니다.
# helm을 통해서 trino를 쿠버네티스에 구성
$ helm install trino -n trino --create-namespace -f values-overrides.yaml ./
NAME: trino
LAST DEPLOYED: Sun Nov 17 05:52:25 2024
NAMESPACE: trino
STATUS: deployed
REVISION: 1
NOTES:
Get the application URL by running these commands:
export NODE_PORT=$(kubectl get --namespace trino -o jsonpath="{.spec.ports[0].nodePort}" services trino)
export NODE_IP=$(kubectl get nodes --namespace trino -o jsonpath="{.items[0].status.addresses[0].address}")
echo http://$NODE_IP:$NODE_PORT
# 구성한 trino 확인
$ kubectl get all -n trino
NAME READY STATUS RESTARTS AGE
pod/trino-coordinator-55c78798c9-bskql 1/1 Running 0 3m46s
pod/trino-worker-f7d84cbf9-7wb7j 1/1 Running 0 3m46s
NAME TYPE CLUSTER-IP EXTERNAL-IP PORT(S) AGE
service/trino NodePort 10.101.139.23 <none> 8080:30450/TCP 3m46s
service/trino-worker ClusterIP None <none> 8080/TCP 3m46s
NAME READY UP-TO-DATE AVAILABLE AGE
deployment.apps/trino-coordinator 1/1 1 1 3m46s
deployment.apps/trino-worker 1/1 1 1 3m46s
NAME DESIRED CURRENT READY AGE
replicaset.apps/trino-coordinator-55c78798c9 1 1 1 3m46s
replicaset.apps/trino-worker-f7d84cbf9 1 1 1 3m46s
NAME REFERENCE TARGETS MINPODS MAXPODS REPLICAS AGE
horizontalpodautoscaler.autoscaling/trino-worker Deployment/trino-worker memory: <unknown>/80%, cpu: <unknown>/20% 1 3 1 3m46sTrino를 구성하면 바로 WEB UI를 사용할 수 있습니다.
아래 이미지가 NodePort로 통해 외부에서 접속한 Trino WEB UI입니다.
보안 설정을 따로 하지 않았기 때문에 패스워드 없이 유저명을 무작위로 넣어서 접속 가능합니다.
쿼리 툴인 Dbeaver로 Trino에 접속해서 쿼리 해보겠습니다.
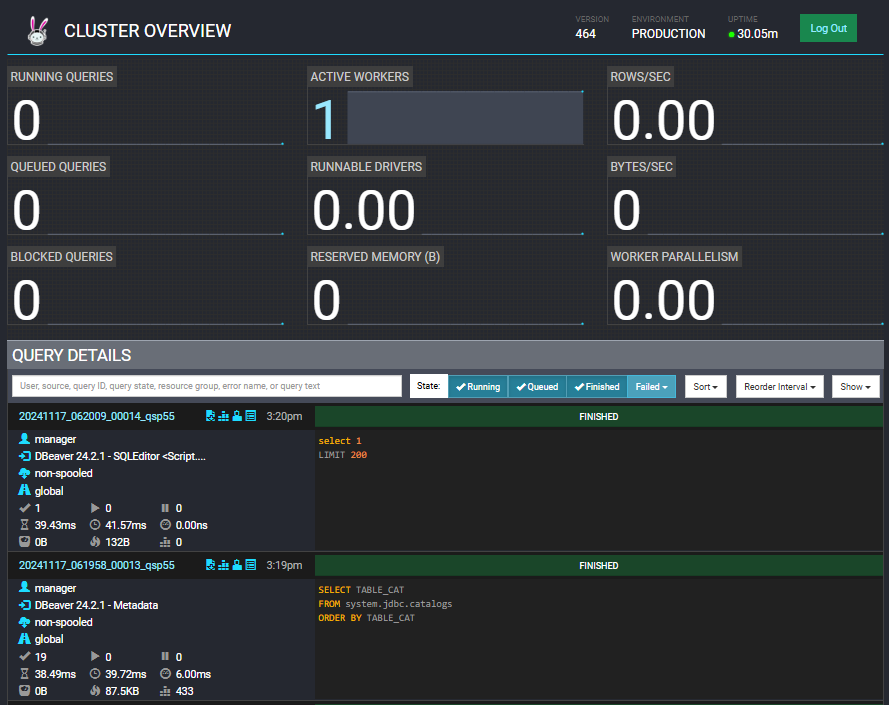
쿼리 결과를 Trino WEB UI에서 확인이 가능합니다.
백엔드 데이터베이스는 없지만 쿼리 이력을 메모리에 일부 저장하여 확인할 수 있게 해 줍니다.
쿼리 아이디를 클릭하면 해당 쿼리의 상세한 정보를 확인할 수 있습니다.
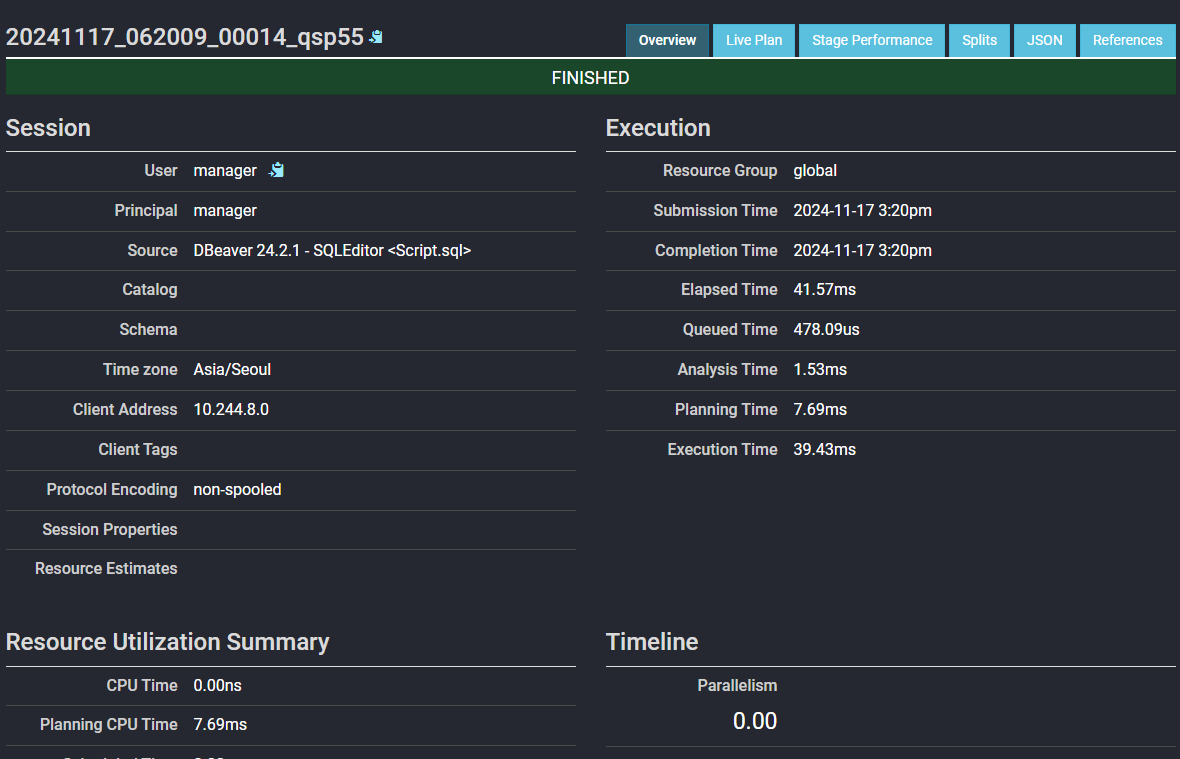
관리자 입장에서 정말 유용한 기능입니다.
다만 쿼리 이력은 메모리에서 관리되기 때문에 최신 데이터만 볼 수 있습니다.
기본 설정에서는 영구적으로 저장하지 않습니다.
쿼리 이력이 얼마나 저장되는지는 아래 2가지 옵션값에 따라 달라집니다.
- query.max-history
- query.min-expire-age
query.max-history는 이력 데이터를 몇 개까지 저장할 것인가이며 디폴트값은 100입니다.
query.min-expire-age는 이력 데이터 저장 만료 시간을 나타내며 디폴트값은 15분입니다.
메모리에 활용하기 때문에 많은 데이터를 저장하고 있을 수 없습니다.
Trino Event Listener
쿼리 이력을 15분 기준으로만 본다면 이슈가 터지면 15분 만에 해결해야 합니다.
그렇다고 시간을 늘려서 메모리 사용률을 높이는 것은 부담이 됩니다.
Trino에서 Event Listener가 있어 해당 문제를 해결할 수 있습니다.
Trino에서 발생하는 이벤트에 대해서 리슨하고 있다가 필요한 후속 작업을 진행할 수 있습니다.
Trino 464 버전 기준으로 아래와 같은 Event Listener를 제공합니다.
- HTTP Event Listener
- Kafka Event Listener
- MySQL Event Listener
- OpenLineage Event Listener
MySQL Event Listener를 활용해서 쿼리 이력 데이터를 MySQL에 저장하려고 합니다.
MySQL Event Listener
MySQL에 Trino 이력 데이터를 넣을 데이터베이스와 접속할 유저를 생성해 줍니다.
MySQL 접속 정보를 Trino Event Listener 설정에 세팅해 주면 됩니다.
이번 포스팅에서는 Trino를 쿠버네티스에 Helm으로 구성하였기 때문에,
Helm values.yaml에 Event Listener 설정 값을 넣어줍니다.
eventListenerProperties:
- event-listener.name=mysql
- mysql-event-listener.db.url=jdbc:mysql://mysql-service.trino.svc.cluster.local:3306/trino?user=trino&password=trinovalues.yaml을 수정하고 helm upgrade 하게 되면 configmap값에
event-listener.properties 부분이 추가되어 있습니다.
$ kubectl get cm -n trino trino-coordinator -o yaml
apiVersion: v1
data:
config.properties: |
coordinator=true
node-scheduler.include-coordinator=false
http-server.http.port=8080
query.max-memory=4GB
query.max-memory-per-node=1GB
discovery.uri=http://localhost:8080
event-listener.properties: |
event-listener.name=mysql
mysql-event-listener.db.url=jdbc:mysql://mysql-service.trino.svc.cluster.local:3306/trino?user=trino&password=trinoMySQL에 해당 데이터베이스에 접속하면 trino_queries 테이블이 생성되어 있습니다.
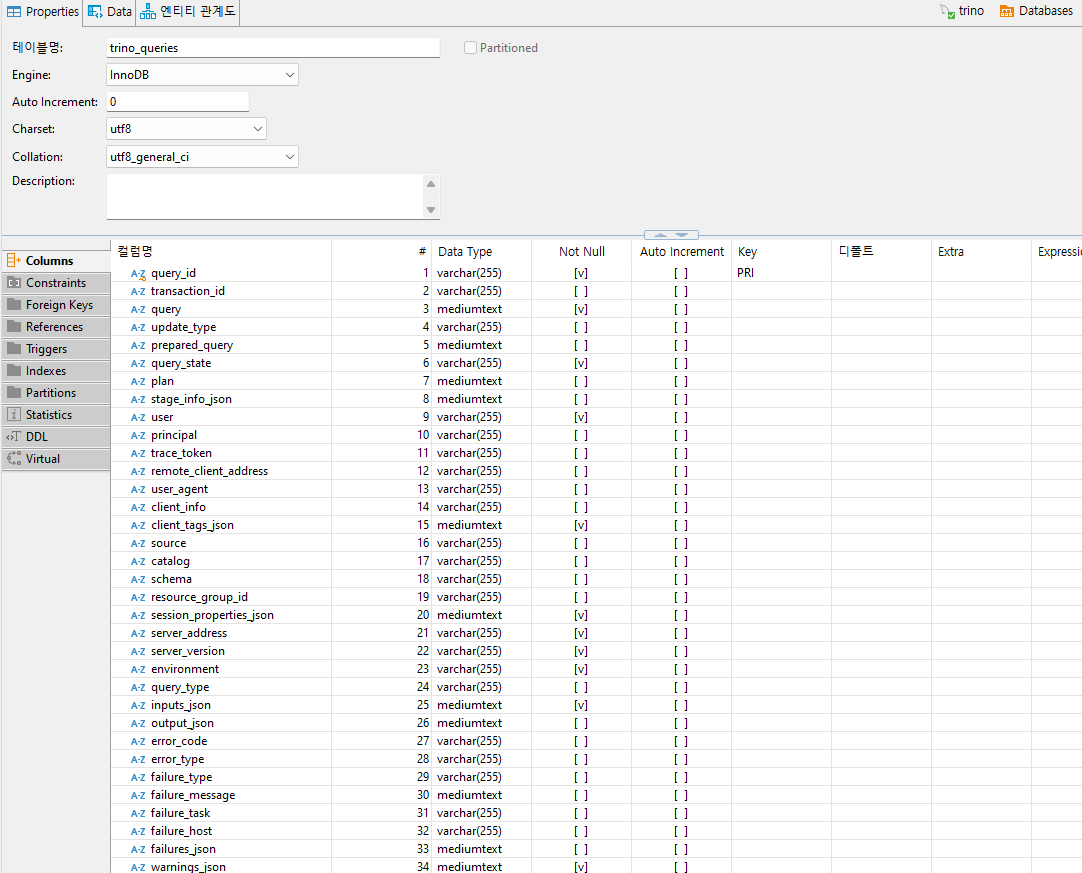
MySQL Event Listener 세팅이 끝났으니 Trino에 쿼리를 날려보겠습니다.
쿼리 후 MySQL trino_queries 테이블을 확인해 보면 쿼리 이력 데이터가 저장된 것을 확인할 수 있습니다.
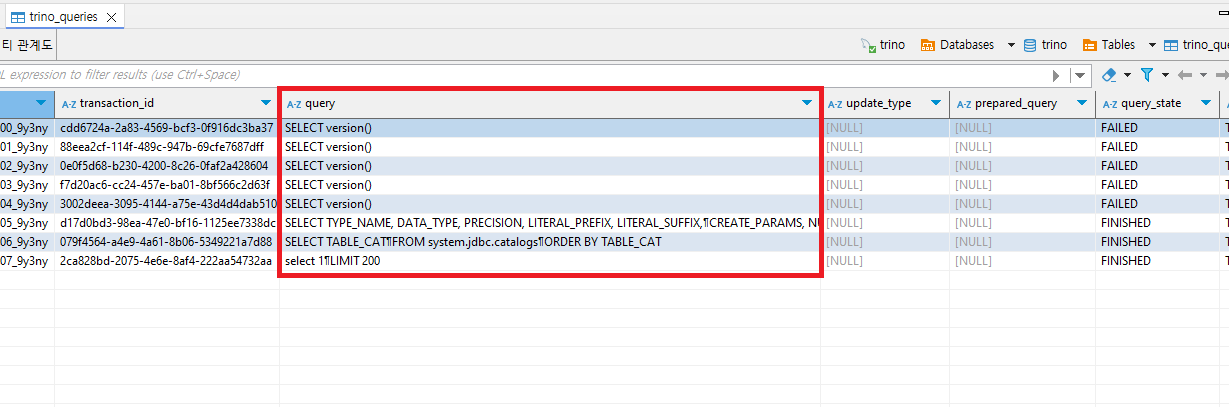
trino_queries 테이블의 데이터는 WEB UI에서 확인한 쿼리 데이터와 동일합니다.
정리
이번 포스팅에서는 Trino 쿼리 이력 데이터를 영구 저장하는 방법을 정리해 보았습니다.
기본 설정에서는 메모리에 일부만 가지고 있어 제한 사항이 있었습니다.
MySQL Event Listener 설정을 통해서 MySQL에 Trino 쿼리 이력을 별도로 저장할 수 있습니다.
Kafka Event Listener도 있기 때문에 Kafka에 저장 후 다양하게 활용하는 것도 좋을 거 같습니다.
[참고사이트]
Web UI — Trino 464 Documentation
Web UI Trino provides a web-based user interface (UI) for monitoring a Trino cluster and managing queries. The Web UI is accessible on the coordinator via HTTP or HTTPS, using the corresponding port number specified in the coordinator Config properties. It
trino.io
Query management properties — Trino 464 Documentation
query.max-history The maximum number of queries to keep in the query history to provide statistics and other information. If this amount is reached, queries are removed based on age.
trino.io
'Data' 카테고리의 다른 글
| Trino 한번 써보겠습니다(3) - AWS S3내 CSV 데이터 조회 (2) | 2023.08.14 |
|---|---|
| Trino 한번 써보겠습니다(2) - Hive Metastore와 AWS S3 연결 (0) | 2023.08.09 |
| Trino 한번 써보겠습니다(1) - Kubernetes에 Trino 설치 (0) | 2023.07.17 |
| GlusterFS 설치 (0) | 2023.02.26 |
| AWS EC2 Nifi 설치 (0) | 2022.11.23 |



