
| 일 | 월 | 화 | 수 | 목 | 금 | 토 |
|---|---|---|---|---|---|---|
| 1 | ||||||
| 2 | 3 | 4 | 5 | 6 | 7 | 8 |
| 9 | 10 | 11 | 12 | 13 | 14 | 15 |
| 16 | 17 | 18 | 19 | 20 | 21 | 22 |
| 23 | 24 | 25 | 26 | 27 | 28 | 29 |
| 30 |
- Python
- Trino
- Operating System
- kubectl
- Kafka
- kubeadm
- MAC address
- OS
- kubernetes
- Spring
- log
- grafana
- Packet
- tcp
- helm
- ip
- zookeeper
- aws s3
- PostgreSQL
- docker
- JavaScript
- jvm
- CSV
- EC2
- AWS
- Network
- airflow
- CVAT
- Vision
- java
- Today
- Total
JUST WRITE
Trino 한번 써보겠습니다(3) - AWS S3내 CSV 데이터 조회 본문

Trino 한번 써보겠습니다(3)
분산 Query Engine 중 가장 핫한 Trino를 설치해 보았습니다.
Kubernetes Cluster에 Hive Metastore를 구성해서 AWS S3에 연결까지 해보았습니다.
Trino 한번 써보겠습니다(2) - Hive Metastore와 AWS S3 연결
Trino 한번 써보겠습니다(2) 분산 Query Engine 중 가장 핫한 Trino를 설치해 보았습니다. Trino 한번 써보겠습니다(1) - Kubernetes에 Trino 설치 Trino 한번 써보겠습니다(1) RDB에서 데이터를 조회할 때 SQL를 통
developnote-blog.tistory.com
- Trino 설치
- Hive Metastore와 AWS S3 연결
- AWS S3내 CSV 데이터 조회
Trino 도전 실습 마지막 포스팅입니다.
이번 포스팅에서는 Trino로 AWS S3에 있는 CSV 데이터를 조회해 보도록 하겠습니다.
Trino Catalog 추가
Trino에서 AWS S3 데이터를 조회하기 전에 hive와 연결을 해줘야 합니다.
Trino에 Hive Connector를 추가해줍니다.
Helm으로 배포한 Trino에서 설정값을 추가해줍니다.
values-override.yaml에 아래 부분을 추가해줍니다.
additionalCatalogs:
hive: |-
connector.name=hive
hive.metastore.uri=thrift://metastore.trino.svc.cluster.local:9083
hive.s3.endpoint=https://s3.ap-northeast-2.amazonaws.com
hive.s3.aws-access-key=****
hive.s3.aws-secret-key=****Helm 명령어를 통해서 설정을 업데이트합니다.
helm upgrade trino -n trino -f values-override.yaml ./변경된 설정값이 적용될 수 있도록 coordinator와 worker를 재시작합니다.
# coordinator 재시작
$ kubectl rollout restart -n trino deployment.apps/trino-coordinator
# worker 재시작
$ kubectl rollout restart -n trino deployment.apps/trino-workerTrino 접속
먼저 작업 PC에서 Trino를 접속해 보도록 하겠습니다.
Trino가 Web UI를 제공하긴 하지만 Dbeaver라는 Database Tool를 활용하도록 하겠습니다.
Dbeaver는 OpenSource로 손쉽게 설치가 가능한 Tool입니다.
Dbeaver는 다양한 Database 연결을 지원하고 있으며 Trino 역시 지원하고 있습니다.
Dbeaver에서 [create database] 누르고 trino를 선택할 수 있습니다.
Trino 접속 정보를 입력해 줍니다.
Trino는 Kubernetes Cluster에 구성하였으며 NodePort로 Service를 외부로 노출하였습니다.
$ kubectl get service -n trino
NAME TYPE CLUSTER-IP EXTERNAL-IP PORT(S) AGE
metastore ClusterIP 10.102.190.147 <none> 9083/TCP 3d18h
mysql-service ClusterIP 10.102.96.24 <none> 3306/TCP 4d18h
mysql-svc-np NodePort 10.101.251.182 <none> 3306:30036/TCP 3d23h
trino NodePort 10.110.205.240 <none> 8080:32157/TCP 27d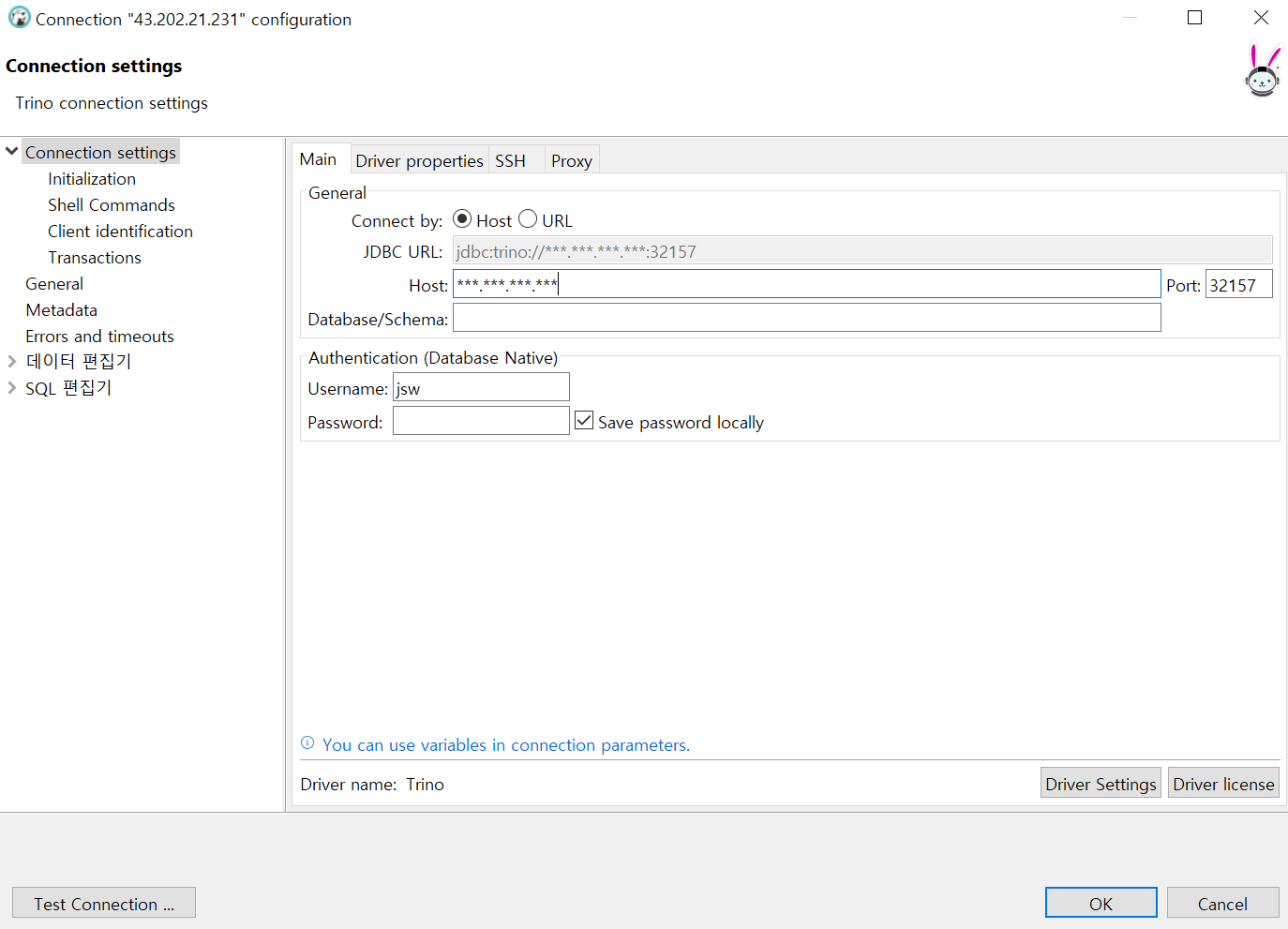
Trino 접속에 성공하면 아래와 같이 Catalog를 확인할 수 있습니다.
hive는 저번 포스팅에서 Hive Metastore 연결한 Catalog입니다.

AWS S3 CSV 업로드
Sample 데이터는 DataHub에 있는 데이터 중에서 선별하였습니다.
DataHub에 있는 데이터 중 세계 항공 정보가 담긴 데이터를 S3에 업로드하였습니다.
Airport Codes
Airport codes. IATA airport code. ICAO airport code. Airport codes from around the world and coordinates. Download data tables in csv (excel) and json formats.
datahub.io
S3에 버킷을 하나 만들고 거기에 해당 CSV 파일을 업로드하였습니다.

Trino 테이블 생성
이제 Trino에서 방금 업로드한 CSV 데이터를 조회하도록 하겠습니다.
Hive Metastore와 연결한 Hive Catalog에 schema를 생성합니다.
생성한 schema 하위에 테이블을 생성합니다.
옵션으로 external_location과 format을 주어서 테이블을 생성합니다.
# schema 생성
create schema hive.airport;
# table 생성
create table hive.airport.codes (
ident varchar,
type varchar,
name varchar,
elevation_ft varchar,
continent varchar,
iso_country varchar,
iso_region varchar,
municipality varchar,
gps_code varchar,
iata_code varchar,
local_code varchar,
coordinates varchar
)
with (
external_location = 's3a://tr-test123/',
format = 'CSV'
);
# select
select * from hive.airport.codes;주의할 점은 format이 CSV라 Data Type이 varchar만 지원되는 점입니다.
다른 Data Type으로 하니 Error가 발생하였습니다.
테이블 생성 후 조회를 해보았습니다.

정리
Trino 기본 실습 시리즈로 Trino 설치부터 Object Storage에 연결, 데이터 조회까지 해보았습니다.
아주 기본적인 부분만 진행한 거라 아직 Trino 성능은 기회가 되면 다음에 정리해 보도록 하겠습니다.
'Data' 카테고리의 다른 글
| [Trino] 너의 흔적을 기록하고 싶어 - 히스토리 데이터 영구 저장 (0) | 2024.11.17 |
|---|---|
| Trino 한번 써보겠습니다(2) - Hive Metastore와 AWS S3 연결 (0) | 2023.08.09 |
| Trino 한번 써보겠습니다(1) - Kubernetes에 Trino 설치 (0) | 2023.07.17 |
| GlusterFS 설치 (0) | 2023.02.26 |
| AWS EC2 Nifi 설치 (0) | 2022.11.23 |



