
| 일 | 월 | 화 | 수 | 목 | 금 | 토 |
|---|---|---|---|---|---|---|
| 1 | ||||||
| 2 | 3 | 4 | 5 | 6 | 7 | 8 |
| 9 | 10 | 11 | 12 | 13 | 14 | 15 |
| 16 | 17 | 18 | 19 | 20 | 21 | 22 |
| 23 | 24 | 25 | 26 | 27 | 28 | 29 |
| 30 |
- ip
- Operating System
- helm
- Kafka
- OS
- grafana
- Trino
- AWS
- zookeeper
- CVAT
- MAC address
- tcp
- Spring
- Python
- PostgreSQL
- CSV
- jvm
- kubeadm
- JavaScript
- EC2
- log
- Packet
- kubectl
- airflow
- kubernetes
- aws s3
- Vision
- Network
- docker
- java
- Today
- Total
JUST WRITE
[LLM] RAG와 LLM을 활용한 자동 분류(1) - VectorDB 구성하기 본문

VectorDB 구성하기
좋은 기회로 사내에서 데이터를 카테고리별로 자동 분류하는 과제를 맡게 되었습니다.
엔지니어이기 때문에 분류 서비스를 만들어 본 적은 없지만,
이번 기회에 다양한 것들을 도전하려고 합니다.
그래서 자동 분류를 RAG와 LLM을 활용해서 해보려고 합니다.
방식을 간단하게 나열해 보면 아래와 같습니다.
- 학습에 쓰일 과거 데이터를 VectorDB에 저장한다.
- 서버에 OpenSource 기반의 LLM을 설치한다.
- 분류를 진행하려는 데이터를 VectorDB에서 유사한 데이터를 찾는다.
- 찾은 데이터를 기반으로 프롬프트를 구성해서 LLM에 어떤 카테고리에 해당하는지 물어본다.
시리즈로 구성해서 위 내용들을 블로그에 정리해보려고 합니다.
이번 포스팅에서는 VectorDB를 구성하고 분류에 참고할 과거 데이터를 저장하려고 합니다.
Milvus 설치
VectorDB 중 하나인 Milvus를 설치하려고 합니다.
현재 사용하고 있는 주요 VectorDB는 아래와 같습니다.
- Pinecone
- Milvus
- Weaviate
- Qdrant
- Chroma
- FAISS (Facebook AI Similarity Search)
- pgvector
그중에서 이번 포스팅에서는 Milvus를 사용하려고 합니다.
Milvus는 오픈 소스 기반이며 커뮤니티가 활발하게 이뤄지고 있습니다.
분산 아키텍처로 지원으로 안정성도 확보하고 있습니다.
MinIO나 S3 같은 Object Storage에 데이터를 저장하는 구조라 스토리지 구성이 부담이 적습니다.
인덱싱 방식을 지원해서 성능을 최적화해 볼 수 있습니다.
쿠버네티스 환경에서도 구성할 수 있고 Milvus lite 버전이 있어 로컬 테스트용으로도 설치 가능합니다.
(Milvus lite를 지원하는 OS는 Linux, MacOS입니다.)
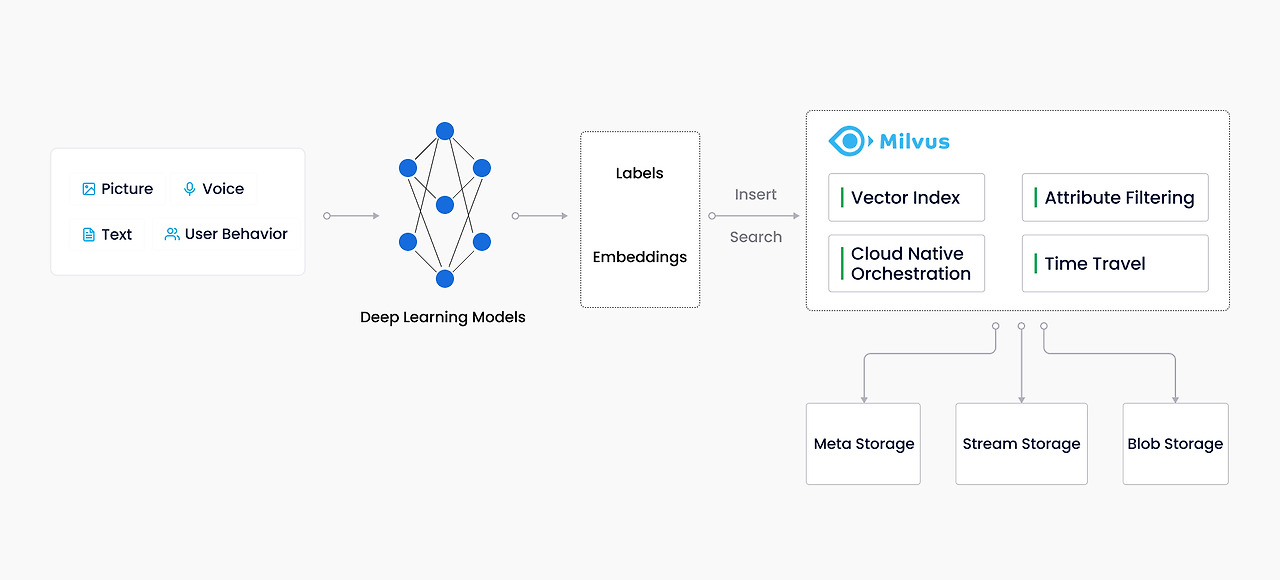
docker-compose로 구성
이번 포스팅에서는 Milvus Standalone 버전을 docker compose로 구성해 보겠습니다.
총 4가지 컨테이너가 실행됩니다.
- etcd -> Meta Storage
- minio -> Blob Storage
- milvus -> VectorDB engine
- attu -> Mivus WEB UI
Minio는 많이 사용되는 Object Storage로 실질적인 데이터 저장소로 쓰이게 됩니다.
etcd는 메타정보를 저장하는 곳으로 쓰입니다.
attu는 오픈 소스로 Milvus 관리용 툴입니다. WEB UI를 제공하고 있습니다.
적절한 path에 볼륨 설정을 한 뒤 아래 compose 파일로 실행합니다.
version: '3.5'
services:
etcd:
container_name: milvus-etcd
image: quay.io/coreos/etcd:v3.5.5
environment:
- ETCD_AUTO_COMPACTION_MODE=revision
- ETCD_AUTO_COMPACTION_RETENTION=1000
- ETCD_QUOTA_BACKEND_BYTES=4294967296
- ETCD_SNAPSHOT_COUNT=50000
volumes:
- ./volumes/milvus/etcd:/etcd
command: etcd -advertise-client-urls=http://127.0.0.1:2379 -listen-client-urls http://0.0.0.0:2379 --data-dir /etcd
minio:
container_name: milvus-minio
image: minio/minio:RELEASE.2023-03-20T20-16-18Z
environment:
MINIO_ACCESS_KEY: minioadmin
MINIO_SECRET_KEY: minioadmin
volumes:
- ./volumes/milvus/minio:/minio_data
command: minio server /minio_data
healthcheck:
test: ["CMD", "curl", "-f", "http://localhost:9000/minio/health/live"]
interval: 30s
timeout: 20s
retries: 3
standalone:
container_name: milvus-standalone
image: milvusdb/milvus:v2.3.3
command: ["milvus", "run", "standalone"]
environment:
ETCD_ENDPOINTS: etcd:2379
MINIO_ADDRESS: minio:9000
volumes:
- ./volumes/milvus/milvus:/var/lib/milvus
ports:
- "19530:19530"
- "9091:9091"
depends_on:
- "etcd"
- "minio"
attu:
container_name: milvus-attu
image: zilliz/attu:v2.4.12
environment:
MILVUS_URL: standalone:19530
ports:
- "8000:3000"
depends_on:
- "standalone"
networks:
default:
name: milvus# docker compose을 통해서 milvus 생성
$ docker-compose up -d
Creating network "milvus" with the default driver
Pulling etcd (quay.io/coreos/etcd:v3.5.5)...
v3.5.5: Pulling from coreos/etcd
dbba69284b27: Pull complete
270b322b3c62: Pull complete
7c21e2da1038: Pull complete
cb4f77bfee6c: Pull complete
e5485096ca5d: Pull complete
3ea3736f61e1: Pull complete
1e815a2c4f55: Pull complete
Digest: sha256:89b6debd43502d1088f3e02f39442fd3e951aa52bee846ed601cf4477114b89e
Status: Downloaded newer image for quay.io/coreos/etcd:v3.5.5
Pulling minio (minio/minio:RELEASE.2023-03-20T20-16-18Z)...
RELEASE.2023-03-20T20-16-18Z: Pulling from minio/minio
c7e856e03741: Pull complete
c1ff217ec952: Pull complete
b12cc8972a67: Pull complete
4324e307ea00: Pull complete
152089595ebc: Pull complete
05f217fb8612: Pull complete
Digest: sha256:6d770d7f255cda1f18d841ffc4365cb7e0d237f6af6a15fcdb587480cd7c3b93
Status: Downloaded newer image for minio/minio:RELEASE.2023-03-20T20-16-18Z
Pulling standalone (milvusdb/milvus:v2.3.3)...
v2.3.3: Pulling from milvusdb/milvus
d5fd17ec1767: Pull complete
0f5a22c44678: Pull complete
72ad4f350efb: Pull complete
2f5ee08a99b8: Pull complete
3fe28e251347: Pull complete
1f27396f6efc: Pull complete
fe556ec02776: Pull complete
Digest: sha256:6145db1368742b717b5a27d53cc568068308dc204d2014c70e8e8faf0869456b
Status: Downloaded newer image for milvusdb/milvus:v2.3.3
v2.4.12: Pulling from zilliz/attu
2d429b9e73a6: Pull complete
590bc9eabc7e: Pull complete
11b54226a0fa: Pull complete
465f246c24c6: Pull complete
64464083a822: Pull complete
cc991b86a68f: Pull complete
964728ba53f9: Pull complete
dc965c2a769e: Pull complete
d3769fbc79b3: Pull complete
677a81c8214c: Pull complete
0d5e29692220: Pull complete
85441f2440c0: Pull complete
9eeca687e63a: Pull complete
Digest: sha256:36a242d51dbd48e75d8378cd735807502403e4040928d77e92aefc644679855f
Status: Downloaded newer image for zilliz/attu:v2.4.12
Creating milvus-minio ... done
Creating milvus-etcd ... done
Creating milvus-standalone ... done
Creating milvus-attu ... doneattu 컨테이너에서 포워딩한 포트로 브라우저에서 확인하면 아래와 같은 화면을 볼 수 있습니다.
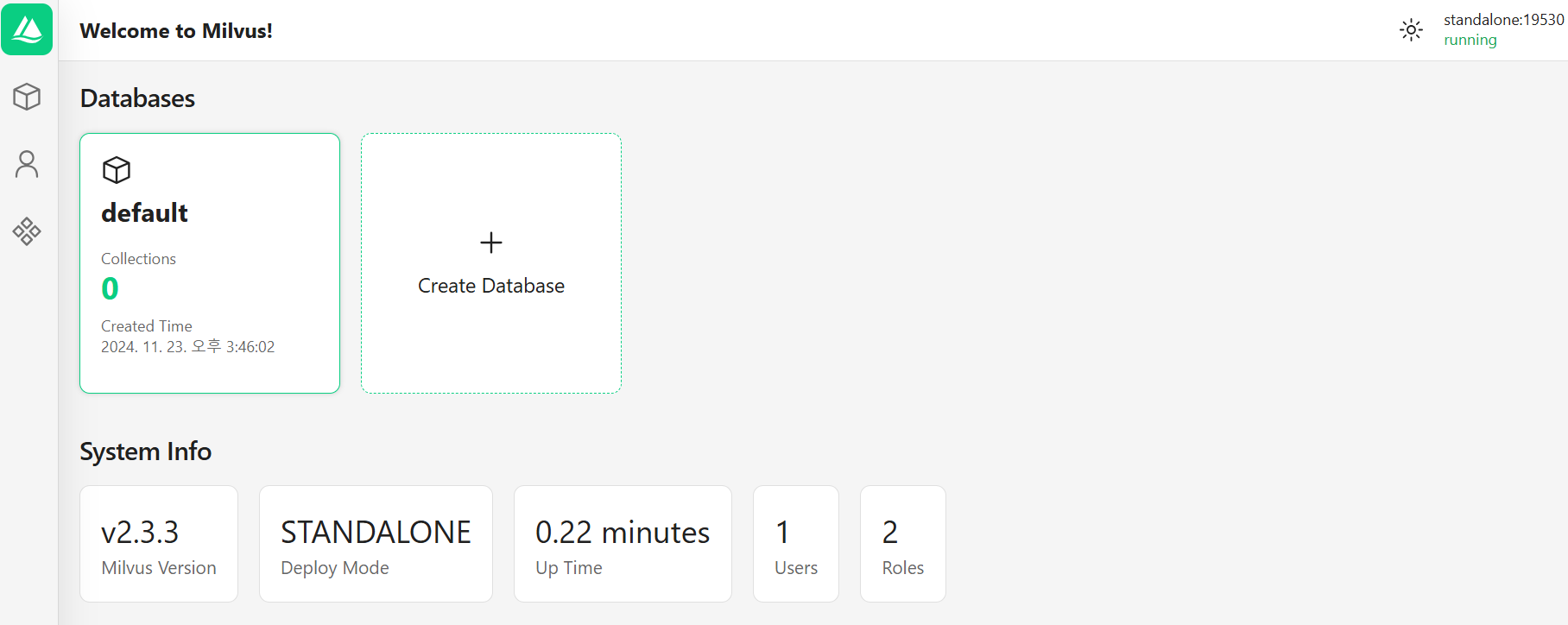
VectorDB에 데이터 저장
Milvus 설치가 완료되었습니다.
이제 LLM이 참고할 수 있도록 외부 지식을 Milvus에 저장하도록 하겠습니다.
LLM에게는 외부에 있는 지식으로 표현되지만 사용자 입장에서는 내부 데이터입니다.
Milvus 파이썬 SDK와 임베딩값을 추출하기 위해 SBERT 라이브러리를 설치합니다.
$ pip install pymilvus sentence-transformersMilvus 컬렉션 구성
Milvus에서는 컬렉션이라는 단위가 있습니다.
데이터를 저장하는 기본 단위로 RDB에서 테이블과 비슷한 개념입니다.
필드, primary key, 인덱스를 가지고 있습니다.
VectorDB이기 때문에 vector 필드를 구성할 수 있으며 dimension값을 지정할 수 있습니다.
# 필드 정의
id_field = FieldSchema(name="id", dtype=DataType.INT64, is_primary=True)
vector_field = FieldSchema(name="vector", dtype=DataType.FLOAT_VECTOR, dim=128)
age_field = FieldSchema(name="age", dtype=DataType.INT64)
name_field = FieldSchema(name="name", dtype=DataType.VARCHAR, max_length=200)
# 스키마 생성
schema = CollectionSchema(
fields=[id_field, vector_field, age_field, name_field],
description="User profiles collection"
)
# 컬렉션 생성
collection = Collection(
name="user_profiles",
schema=schema,
using='default'
)
테스트 데이터로 VOC 데이터를 LLM을 생성해 보았습니다.
내용을 보고 카테고리를 자동으로 분류하는 서비스를 만들어볼 예정입니다.
제목과 내용을 기반으로 임베딩을 생성하며 임베딩값을 vector 필드에 넣을 예정입니다.
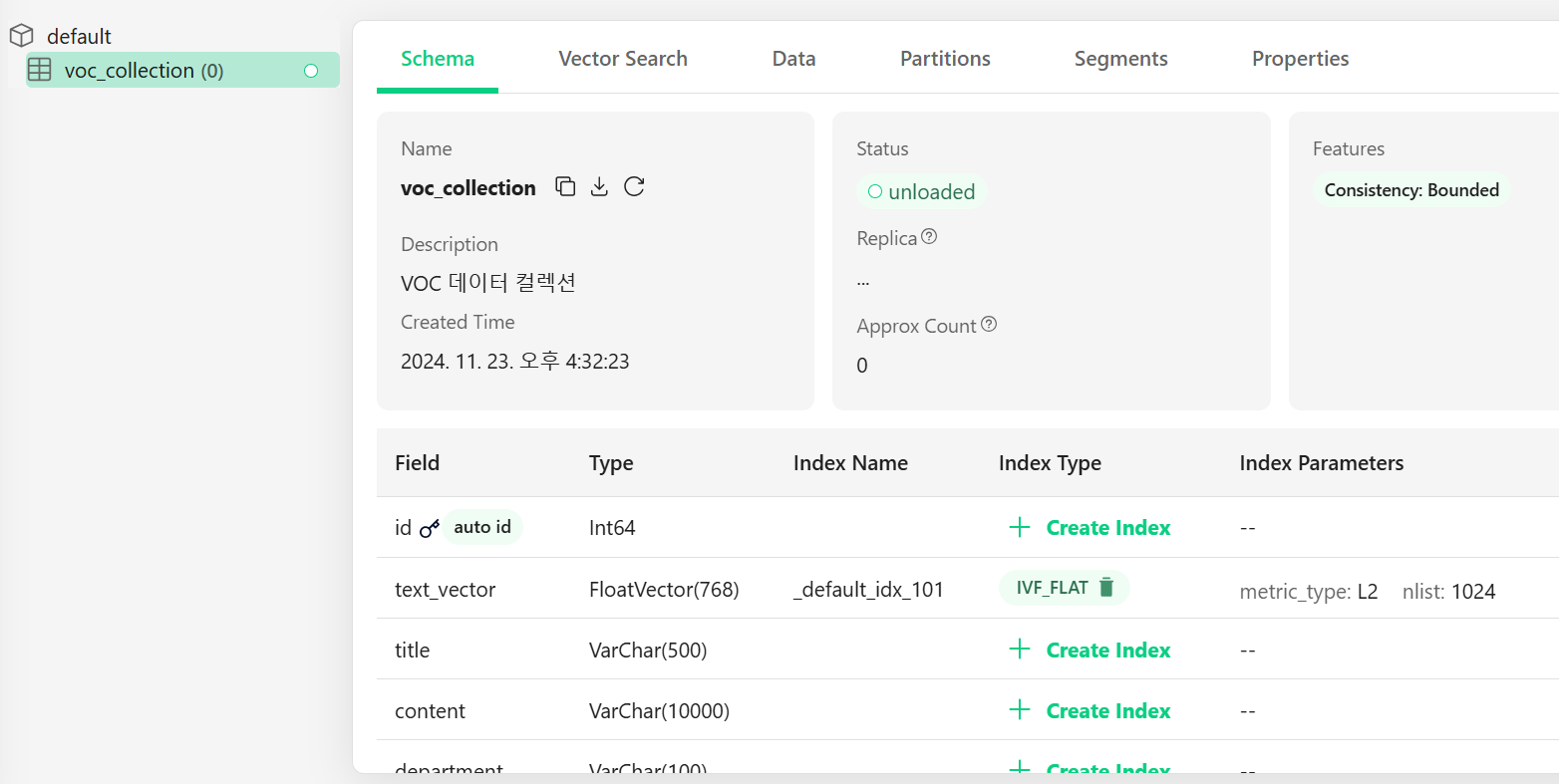
컬렉션을 생성하면 attu WEB UI에서도 확인할 수 있습니다.
SBERT로 임베딩 생성
분류를 하려고 하는 데이터와 유사한 데이터를 기반으로 프롬프트를 구성하려고 합니다.
유사 데이터 기반 외부 지식이 더해진 프롬포트가 LLM에 더 좋은 결과를 얻을 수 있습니다.
유사한 데이터를 검색하기 위해 해당 내용을 임베딩해서 VectorDB에 저장해야 합니다.
이번 포스팅에서는 SBERT를 이용해서 임베딩을 생성합니다.
SBERT는 Sentence-BERT는 BERT를 기반으로 합니다.
문장 임베딩을 생성하는데 특화되어 있는 모델입니다.
문장 간의 유사도를 계산하기 위한 의미 있는 문장 임베딩을 생성할 때 주로 쓰입니다.
pip install sentence-transformers
from sentence_transformers import SentenceTransformer
model = SentenceTransformer('sentence-transformers/paraphrase-multilingual-mpnet-base-v2')다국어지원이 가능하며 가장 범용적인 paraphrase-multilingual-mpnet-base-v2를 사용합니다.
encode 함수를 사용하면 쉽게 임베딩값을 생성할 수 있습니다.
# 전체 텍스트 임베딩 생성
# 제목과 내용 합치기
combined_texts = [f"{title} {content}"
for title, content in zip(df['title'], df['content'])]
# 임베딩 생성
text_vectors = model.encode(combined_texts)컬렉션 스키마 구성은 id, title, content, category, vector 필드입니다.
id값은 primary key로 자동 생성하도록 설정하였습니다.
제목(title)과 내용(content)을 기반으로 주제(category)를 자동으로 분류하려고 합니다.
# 데이터 준비
titles = df['title'].tolist()
contents = df['content'].tolist()
categories = df['category'].tolist()
# 데이터 삽입
entities = [
text_vectors.tolist(),
titles,
contents,
categories
]
collection.insert(entities)성공적으로 Milvus에 데이터를 넣으면 WEB UI에서도 확인할 수 있습니다.

정리
이번 포스팅에서는 RAG와 LLM을 활용해 자동분류하기 첫 번째 포스팅이었습니다.
VectorDB인 Milvus를 구성하였습니다.
SBERT를 이용해서 데이터에서 임베딩값을 생성해서 VectorDB에 저장하였습니다.
다음 포스팅에서는 오픈 소스 기반의 LLM을 서버에 구축해보도록 하겠습니다.
[참고사이트]
Run Milvus with Docker Compose | Milvus Documentation
Learn how to install Milvus standalone with Docker Compose. | v2.4.x
milvus.io
GitHub - zilliztech/attu: The GUI for Milvus
The GUI for Milvus. Contribute to zilliztech/attu development by creating an account on GitHub.
github.com
SentenceTransformers Documentation — Sentence Transformers documentation
www.sbert.net
'AI' 카테고리의 다른 글
| [Embedding] Sparse vs Dense 임베딩 (0) | 2025.07.02 |
|---|---|
| [LLM] RAG와 LLM을 활용한 자동 분류(2) - Ollama 세팅하기 (0) | 2024.12.14 |
| 하이퍼 파리미터 튜닝(1) - Tracking System Mlflow 세팅 (0) | 2024.10.12 |
| [Vision] Click 한 번에 Segmentation?! - CVAT에 SAM 적용 (2) | 2024.01.17 |
| [Vision] GraphDB로 얼굴인식을?!?!(3) - GraphDB로 얼굴 인식하기 (0) | 2023.05.11 |



