
| 일 | 월 | 화 | 수 | 목 | 금 | 토 |
|---|---|---|---|---|---|---|
| 1 | 2 | 3 | 4 | |||
| 5 | 6 | 7 | 8 | 9 | 10 | 11 |
| 12 | 13 | 14 | 15 | 16 | 17 | 18 |
| 19 | 20 | 21 | 22 | 23 | 24 | 25 |
| 26 | 27 | 28 | 29 | 30 | 31 |
- EC2
- Operating System
- airflow
- dns
- CVAT
- PostgreSQL
- grafana
- Terraform
- Packet
- jvm
- kubeadm
- kubernetes
- Network
- kubectl
- ip
- aws s3
- java
- MAC address
- OS
- Spring
- zookeeper
- Python
- docker
- CSV
- tcp
- Kafka
- AWS
- helm
- JavaScript
- log
- Today
- Total
JUST WRITE
따릉이 대여소 정보 Dashboard 구성(1) - Python으로 데이터 정제 본문
AWS Cloud 실습을 위해 진행한 개인 프로젝트를 정리한 글입니다.

AWS Cloud를 공부하기 위해 따릉이 대여서 정보 Dashboard 구성 프로젝트를 진행하였다.
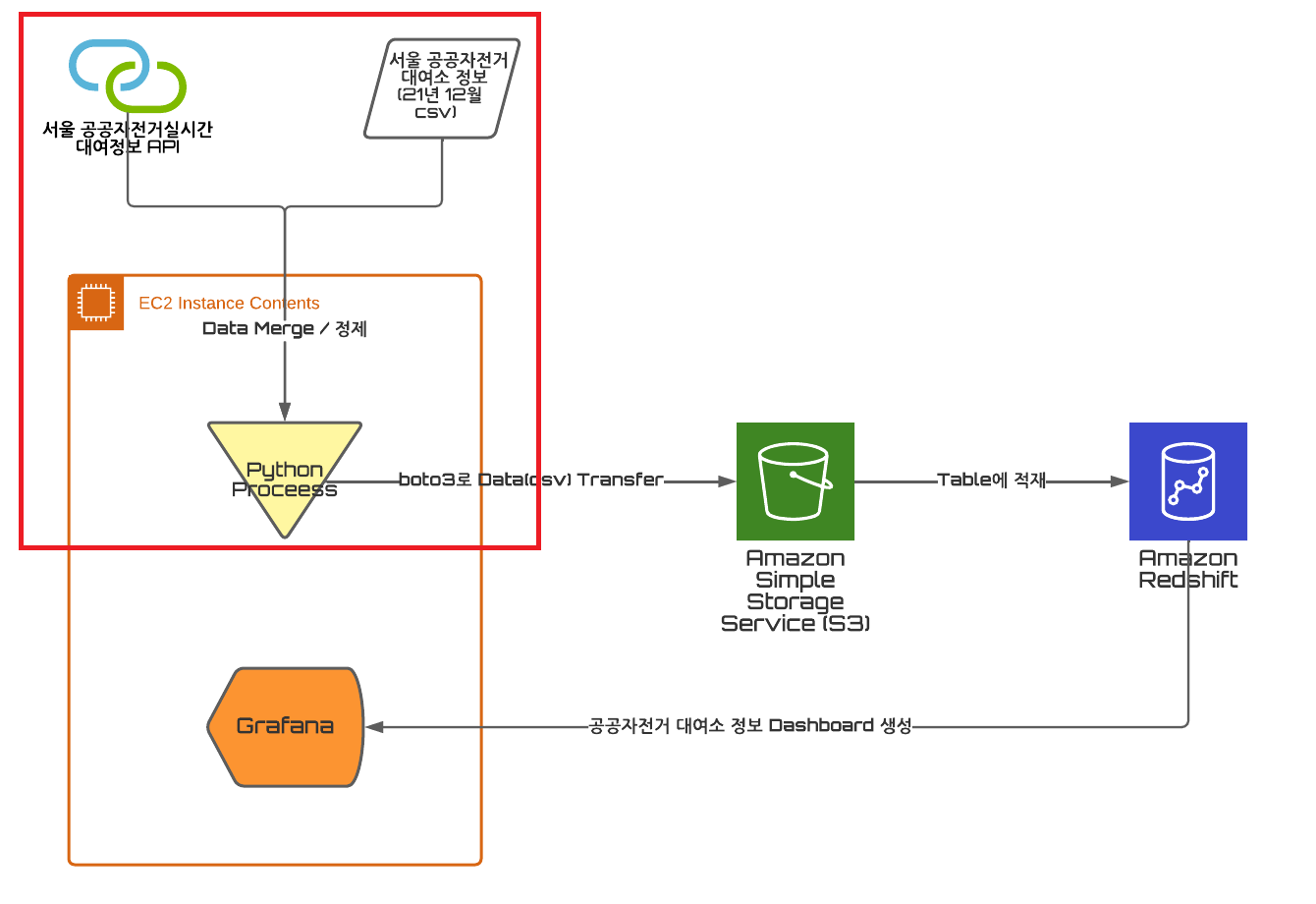
위 그림에서 빨간색 부분인 Data 정제 부분을 먼저 진행하였다.
서울 공공데이터에서 2가지 데이터를 가져와서 통합 및 정제를 진행하였다.
- 서울특별시 공공자전거 대여소 정보(21년 12월 기준) -> csv 파일
- 서울특별시 공공자전거 실시간 대여 정보 -> OpenAPI로 제공
실시간 대여 정보에는 아래와 같은 정보가 존재한다.
| 출력명 | 출력설명 |
| rackTotCnt | 거치대 개수 |
| stationName | 대여소 이름 |
| parkingBikeTotCnt | 자전거 주차 총 건수 |
| shared | 거치율 |
| stationLatitude | 위도 |
| stationLongitude | 경도 |
| stationId | 대여소 ID |
따릉이 대여소의 위도, 경도 정보가 존재하지만 주소 정보가 존재하지 않았다.
공공자전거 대여소 정보(csv)에서 대여소 소재 구명과 상세 주소를 실시간 대여 정보와 Merge 하였다.
Python을 통해서 Merge를 진행하였다.
Python code는 일부만 첨부하였다.
Python 데이터 정제
csv 파일 읽기
서울 공공데이터에서 제공하는 csv 파일은 대부분 Encoding은 cp949이다.
공공자전거 대여소 정보 역시 Encoding이 cp949였다.
먼저 Encoding을 cp949에서 UTF-8로 변환하였다.
그다음 pandas pakcage를 통해 파일을 읽어 Dataframe 형식으로 변환하였다.
import pandas as pd
def update_seoul_rent_bike_station_csv() :
# 서울 공공자전거 대여소 정보(21년 12월 기준)
# 대여소별 상세정보 가져오기
df = pd.read_csv('seoul_rent_bike_station_info_21y_12m_after.csv', skiprows=[1,2,3,4], encoding='utf-8')
# 대여소 정보 csv 파일 정제
# key = '대여소\r\n번호'
# Dataframe Address Column rename
df = df.rename(columns = {'대여소\r\n번호': 'stationNum', '소재지(위치)': 'gu', 'Unnamed: 3' : 'address'} , inplace = False)
return dfOpenAPI 요청
실시간 대여 정보는 OpenAPI로 제공되었다.
Python requests package를 통해서 API 요청하였다.
Json 형식으로 오는 데이터를 dictionary 객체로 변환하여 처리하였다.
import requests
def find_code_from_json (dic_str) :
search_list = [dic_str]
for search in search_list :
for key in search.keys() :
if key == 'CODE' :
return search
elif type(search[key]) is dict :
search_list.append(search[key])
def request_seoul_api(start_index, end_index) :
with open('api_key.bin', encoding='UTF-8') as api_key_file :
api_key = api_key_file.read()
url = f'{g_api_host}/{api_key}/{g_type}/{g_service}/{start_index}/{end_index}/'
return requests.get(url).json()데이터 정제
OpenAPI로 받은 실시간 대여 정보와 csv 파일로 읽은 대여소 정보 Data를 합쳤다.
그리고 일별로 특정 시간에 수집할 계획이라서 수집 일자를 각 Data마다 넣어주었다.
def make_csv_for_result_of_api(station_csv_df, response) :
result_json = response.get('rentBikeStatus').get('row')
no_address_list = []
for station in result_json :
update_station_dict(station)
row = station_csv_df.loc[station_csv_df['stationNum'] == station['stationNum']] # type DataFrame
if not row.empty :
station['address'] = re.sub('\r\n', ' ', row.address.item()) # 상세주소
station['gu'] = row.gu.item() # 구
else :
# logging.error('No Address of station : ' + station['stationName'])
no_address_list.append(station['stationName'])
result_df = pd.DataFrame.from_dict(result_json)
result_df = result_df[
['stationId', 'stationNum', 'stationName', 'gu', 'address', 'stationLatitude', 'stationLongitude', 'rackTotCnt', 'parkingBikeTotCnt', 'shared', 'collectionDate']
]
file_name = 'seoul_rentbike_info_{}.csv'.format(g_collection_date.strftime('%m_%d_%Y'))
result_df.to_csv(file_name, encoding='UTF-8', index=False)
if len(no_address_list) != 0 :
with open('no_address_list.txt', 'w', encoding='UTF-8') as outfile:
for station in no_address_list :
outfile.write(station + '\n')최종 결과물로 csv 파일을 만들었다.
stationId,stationNum,stationName,gu,address,stationLatitude,stationLongitude,rackTotCnt,parkingBikeTotCnt,shared,collectionDate
ST-2318,3579,3579.광진 캠퍼스시티,광진구,동일로178,37.54788971,127.06745148,20,9,45,02/11/2022
ST-2320,3581,3581.광진광장,광진구,광나루로389,37.54747009,127.07396698,15,1,7,02/11/2022
ST-2321,3582,3582.화양동 우체국,광진구,광나루로356,37.54798889,127.06950378,14,12,86,02/11/2022
ST-2325,3586,3586.군자역 비채온 오피스텔,광진구,광진구 천호대로 530(군자동),37.55771255,127.07727051,8,10,125,02/11/2022
...
...AWS EC2 실행
EC2 인스턴스 생성
Python 코드를 EC2 환경에서 실행하기로 결정하였다.
AWS Lambda를 고려했지만 Grafana를 설치할 환경도 필요해 EC2에서 Python 코드를 실행하기로 결정하였다.
EC2 인스턴스는 Free tier로 할 수 있는 기본적인 AMI 중 하나로 생성하였다.

Python package 설치
EC2에서 Python 코드를 실행하기 위해서 Python Package 설치하였다.
아래 command로 Python3 설치 유무를 확인한다.
sudo yum list installed | grep -i python3보통 EC2 환경에서는 Python3가 설치되어 있지만 없으면 아래 command로 설치한다.
sudo yum install python3 -y그리고 필요한 Python Package 설치하였다.
다음 과정인 AWS S3에 파일 Upload에 필요한 Package인 boto3도 같이 설치해준다.
pip3 install requests pandas boto3 scheduleEC2에서 Python Code를 실행하기 전에 추가적으로 해야 할 작업이 있다.
정제한 따릉이 대여소 Data CSV 파일을 AWS S3에 Upload 해야 한다.
Upload 하는 작업을 Python으로 작업하려고 한다.
자세한 사항은 다음 글에서 이어서 정리해보려 한다.
'Cloud' 카테고리의 다른 글
| What is Redshift? (0) | 2022.02.15 |
|---|---|
| 따릉이 대여소 정보 Dashboard 구성(2) - AWS S3 파일 업로드 (0) | 2022.02.15 |
| 따릉이 대여소 정보 Dashboard 구성(0) - 시작 (0) | 2022.02.13 |
| What is Amazon EC2? (0) | 2022.02.12 |
| What is Amazon S3? (0) | 2022.02.11 |



