
| 일 | 월 | 화 | 수 | 목 | 금 | 토 |
|---|---|---|---|---|---|---|
| 1 | 2 | 3 | 4 | |||
| 5 | 6 | 7 | 8 | 9 | 10 | 11 |
| 12 | 13 | 14 | 15 | 16 | 17 | 18 |
| 19 | 20 | 21 | 22 | 23 | 24 | 25 |
| 26 | 27 | 28 | 29 | 30 | 31 |
- tcp
- MAC address
- aws s3
- java
- zookeeper
- helm
- EC2
- PostgreSQL
- airflow
- Operating System
- Kafka
- kubernetes
- CSV
- Network
- AWS
- ip
- grafana
- docker
- JavaScript
- kubeadm
- jvm
- Spring
- Python
- OS
- CVAT
- Terraform
- log
- kubectl
- Packet
- dns
- Today
- Total
JUST WRITE
[카이제곱검정(1)] 부서별 업무 환경이 질환에 영향을 미칠까? 본문

부서별 업무 환경이 질환에 영향을 미칠까?
프로젝트에서 데이터 분석 업무를 맡게 되었습니다.
그중 하나가 직원 건강검진 데이터를 분석하는 것이었습니다.
개인 정보 보안 때문에 제한된 정보만으로 분석하게 되었습니다.
건강검진 데이터는 아래와 같은 형태로 되어 있었습니다.
| 연령대 | 부서 | 고혈압 | 당뇨 | 빈혈 |
| 20대 | A 부서 | A | A | A |
| 50대 | B 부서 | D1 | C2 | A |
2022년부터 데이터를 관리하기 시작해서 3년 치 정도의 데이터만 엑셀로 관리되고 있었습니다.
데이터는 총 700건 정도밖에 되지 않았습니다.
작은 데이터 셋으로도 의미 있는 인사이트를 얻을 수 있을지 고민하였습니다.
데이터를 보고 아래와 같은 궁금증이 생겼습니다.
- 연령대가 높을수록 질병 발생률이 높을까?
- 부서별 업무 환경이 영향을 미칠까?
- 이게 단순한 우연일까? 데이터로 증명할 수 없을까?
이러한 궁금증을 해결하기 위해서 생각한 것이 카이제곱 검정(chi-squared test)이었습니다.
카이제곱 검정
카이제곱 검정은 두 범주형 변수 관계에 대해 분석하는 방법입니다.
1900년에 칼 피어슨이 처음으로 고안했다고 알려져 있습니다.
관찰 데이터(observed value)와 기대한 데이터가(expected value)의 차이가 우연인가에서 시작되었습니다.
카이제곱에서 카이(Chi)는 그리스 문자로 C에 해당하며 Contingency(우연성)에서 유래된 것입니다.
아래 검정 통계량에서도 편차가 핵심입니다.
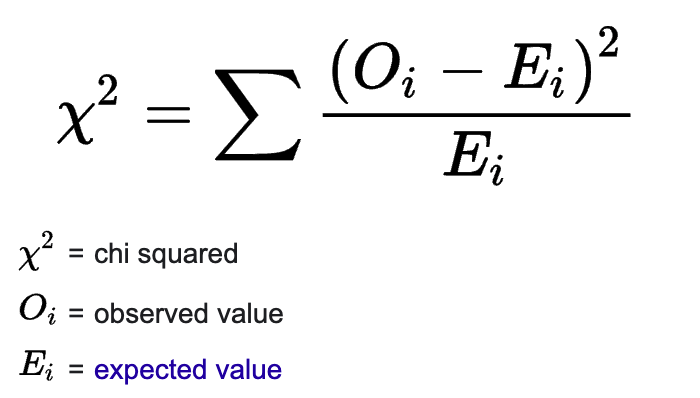
카이제곱 검정은 크게 3가지 목적으로 사용할 수 있습니다.
| 목적 | 예시 | 가설 |
| 적합도 검정 | 고혈압 정상이 전체 중이 70% 정도 나올 것인가? | 귀무가설(H0) : 관찰 분포 = 기대분포 대립가설(H1) : 관찰 분포 ≠ 기대분포 |
| 동질성 검정 | A부서와 B부서의 고혈압 정상 비율 분포가 같은가? | 귀무가설(H0) : 집단1 분포 = 집단2 분포 대립가설(H1) : 집단1 분포 ≠ 집단2 분포 |
| 독립성 검정 | 부서와 고혈압 상태가 서로 관련이 있는가? | 귀무가설(H0) : 두 변수는 독립적 대립가설(H1) : 두 변수는 의존적 |
이번에는 카이제곱 검정에서 독립성 검정을 목적으로 진행하였습니다.
왜 카이제곱 검정인가?
카이제곱 검정으로 검진 데이터를 분석하는 이유는 3가지입니다.
첫 번째는 건강검진 데이터는 범주형 데이터로 구성되어 있습니다.
- 연령대 : 20대, 30대, 40대, 50대 (순서형 범주)
- 부서 : A 부서, B 부서, C부서 ... (명목형 범주)
- 검진 결과 : 아래 코드표 참고

카이제곱 검정은 이러한 범주형 데이터의 관계를 분석할 때 사용됩니다.
두 번째는 카이제곱 검정의 독립성 검정을 통해 위에서 제기한 궁금증에 대해서 분석할 수 있습니다.
아래와 같이 귀무가설과 대립가설을 세울 수 있습니다.
- 귀무가설(H0) : 두 변수는 독립적 -> '부서와 고혈압은 관계없다'
- 대립가설(H1) : 두 변수는 서로 의존 -> '부서 업무 환경에 따라 고혈압 발생률이 다르다'
마지막으로 제한된 데이터의 규모입니다.
약 700건의 적은 데이터이기 때문에 예측 모델 설계는 힘들다고 판단하였습니다.
적은 데이터로도 해당 검정을 통해 해석하기 쉬운 결과가 나올 수 있다고 판단하였습니다.
분석 실시
분석 가설은 아래와 같이 설정하였습니다.
부서별 건강상태 차이 : 업무 환경에 따라 특정 질병 발생률이 다를 것이다
데이터 구조
데이터는 크게 3가지로 구분할 수 있습니다.
부서명은 보안 상 알파벳으로 표시하였습니다.
- 연령대 -> 20대, 30대, 40대, 50대
- 부서 -> A 부서, B 부서, C 부서, D 부서, E 부서
- 검진 항목 별 코드
- 검진 항목 -> 간장질환, 고혈압, 당뇨, 비만, 신장질환 등
- 정상 -> A
- 질환 의심 -> C, C1, C2
- 질환 -> D1, D2
데이터 전처리
데이터 전처리는 크게 2가지로 나눠서 진행하였습니다.
먼저 결측치를 제거하였습니다.
부서나 검진항목에 대한 결과 데이터가 없을 경우 제거하였습니다.
그리고 검진 항목을 크게 3가지 항목(정상, 질환의심, 질환)으로 범주화하였습니다.
import pandas as pd
df = pd.read_csv('./검진데이터.csv')
def categorize_level(code):
if pd.isna(code) or code == 'U':
return None # 결측치/미분류는 제외
elif code in ['A', 'A(B)']:
return '정상'
elif code in ['C', 'C1', 'C2', 'CN']:
return '질환의심'
elif code in ['D1', 'D2', 'DN']:
return '질환'
else:
return None
df[disease_category] = df[disease].apply(categorize_level)카이제곱 검정 시행
카이제곱 검정 분석에는 교차표를 가지고 분석합니다.
교차표는 항목을 각각 행과 열로 배열하여 교차되는 항목에 대해 빈도를 나타낸 표입니다.
다음은 부서와 고혈압에 대한 교차표 예시입니다.
import pandas as pd
pd.crosstab(df['부서'], df['고혈압_category'])
정상 질환의심 질환
A부서 180 20 50
B부서 80 140 30
..
..
..데이터가 데이터프레임 형태면 pandas에서 제공하는 함수로 쉽게 교차표를 생성할 수 있습니다.
scipy 라이브러리를 통해서 카이제곱 검정을 할 수 있습니다.
import pandas as pd
from scipy.stats import chi2_contingency
contingency_table = pd.crosstab(df['부서'], df['고혈압_category'])
chi2_stat, p_value, dof, expected = chi2_contingency(contingency_table)
print(f"카이제곱 통계량: {chi2_stat:.4f}")
print(f"p-value: {p_value:.4f}")
print(f"자유도: {dof}")
if p_value < 0.05:
print("결과: 부서와 고혈압 간에 통계적으로 유의한 관계가 있습니다!")
else:
print("결과: 부서와 고혈압 간에 유의한 관계를 찾을 수 없습니다.")
scipy 라이브러리에서 chi2_contingency 함수를 통해서 카이제곱 검정을 할 수 있습니다.
4개의 반환값을 확인할 수 있습니다.
- chi2_stat -> 검정통계량, 실제 데이터와 독립성 가정 간의 차이 크기
- p_value -> 우연히 발생할 확률, 보통 0.05보다 작으면 귀무가설을 기각하고 증명하려던 가설이 맞다고 볼 수 있음
- dof -> 자유도, 교차표에서 자유롭게 변할 수 있는 셀의 개수
- expected -> 기대빈도 행렬, 립성 가정하에서의 이론적 빈도
p_value가 0.05보다 낮으면 귀무가설을 기각하고 두 변수가 상관있다고 판단합니다.
여기에서는 부서에 따라 고혈압 질환 비율이 다르다고 판단합니다.
이렇게 검진항목별로 부서와 교차표를 생성해서 카이제곱 검정을 실시해 보았습니다.
보안 상 결과를 올리지 않겠습니다.
결과
'부서별 업무 환경이 질환에 영향을 미칠까'라는 질문에 대한 답을 찾기 위해 카이제곱 검정을 하였습니다.
범주형 변수들 간의 관계를 독립성 검정을 진행하였습니다.
카이제곱 검정으로 부서와 검진항목별로 독립적인지 연관이 있는지 분석해 보았습니다.
다음 포스팅에서 사후 분석을 통해서 더 깊이 분석해 보겠습니다.
카이제곱 검정으로 관계가 유의한 지를 보았다면 이제는 구체적으로 어떤 관계인지 분석해 보겠습니다.