
| 일 | 월 | 화 | 수 | 목 | 금 | 토 |
|---|---|---|---|---|---|---|
| 1 | ||||||
| 2 | 3 | 4 | 5 | 6 | 7 | 8 |
| 9 | 10 | 11 | 12 | 13 | 14 | 15 |
| 16 | 17 | 18 | 19 | 20 | 21 | 22 |
| 23 | 24 | 25 | 26 | 27 | 28 | 29 |
| 30 |
- CVAT
- JavaScript
- MAC address
- tcp
- Network
- aws s3
- log
- Spring
- airflow
- PostgreSQL
- OS
- EC2
- zookeeper
- Kafka
- java
- docker
- AWS
- kubectl
- helm
- Operating System
- CSV
- ip
- grafana
- jvm
- kubeadm
- Python
- Vision
- Packet
- Trino
- kubernetes
- Today
- Total
JUST WRITE
뭐야?! No Space left on device?! - Airflow db clean 본문

뭐야?! No Space left on device?!
Airflow를 Kubernetes Cluster에 Helm으로 구성하여 운영하고 있습니다.
Airflow Backend Database로는 PostgreSQL을 사용하고 있습니다.
Product 단계에서는 외부에 구축된 PostgreSQL을 연결해 사용해야 합니다.
하지만 내부 사정으로 Helm에 포함된 PostgreSQL을 사용하고 있습니다.
Airflow Helm Chart.lock 파일을 보면 Bitnami에서 제공하는 PostgreSQL을 사용합니다.
dependencies:
- name: postgresql
repository: https://charts.bitnami.com/bitnami
version: 12.10.0
digest: sha256:731562ef1f62ee687121df2d44ff8131a73aa63841f6cac858c30748ad349d55
generated: "2023-08-25T13:23:48.02337-06:00"구축 후 2년 가까이 별문제 없이 사용하고 있었습니다.
하지만 결국 문제가 터졌습니다.
Airflow Scheduler의 Pod이 Restart를 계속하더니 CrashLoopBackOff 상태였습니다.
Scheduler log를 확인하니 PostgreSQL connection이 안 되고 있었습니다.
...
...
File "/home/airflow/.local/lib/python3.6/site-packages/sqlalchemy/engine/base.py", line 1277, in _execute_context
cursor, statement, parameters, context
File "/home/airflow/.local/lib/python3.6/site-packages/sqlalchemy/engine/default.py", line 608, in do_context
cursor.execute(statement, parameters)
sqlalchemy.exc.OperationalError: (psycopg2.errors.DiskFull) could not extend file "base/13104/16805": No space left on device
HINT: Check free disk space.PostgreSQL data를 저장하는 공간에 100%를 차지하고 있었습니다.
No Space left on device 에러를 보이고 있었습니다.
$ kubectl exec -it pod/airflow-postgresql-0 -n airflow -- df -h
Filesystem Size Used Avail Use% Mounted on
...
...
/dev/rbd6 7.9G 7.8G 0 100% /bitnami/postgresql
...
...PV 용량 늘리기
먼저 PostgreSQL에 할당된 PV Size를 체크하였습니다.
PV의 용량은 8Gi였습니다.
따로 설정하지 않았었는데 기본값이 8Gi였습니다.
아래는 Bitnami PostgreSQL Helm Chart values.yaml 중 일부입니다.
persistence:
## @param primary.persistence.enabled Enable PostgreSQL Primary data persistence using PVC
##
enabled: true
## @param primary.persistence.existingClaim Name of an existing PVC to use
##
existingClaim: ""
## @param primary.persistence.mountPath The path the volume will be mounted at
## Note: useful when using custom PostgreSQL images
##
mountPath: /bitnami/postgresql
## @param primary.persistence.subPath The subdirectory of the volume to mount to
## Useful in dev environments and one PV for multiple services
##
subPath: ""
## @param primary.persistence.storageClass PVC Storage Class for PostgreSQL Primary data volume
## If defined, storageClassName: <storageClass>
## If set to "-", storageClassName: "", which disables dynamic provisioning
## If undefined (the default) or set to null, no storageClassName spec is
## set, choosing the default provisioner. (gp2 on AWS, standard on
## GKE, AWS & OpenStack)
##
storageClass: ""
## @param primary.persistence.accessModes PVC Access Mode for PostgreSQL volume
##
accessModes:
- ReadWriteOnce
## @param primary.persistence.size PVC Storage Request for PostgreSQL volume
##
size: 8Gi일단 Airflow 정상화를 위해서 PostgreSQL PV를 늘리기로 하였습니다.
PV의 StorageClass로 rook-ceph-block를 사용하고 있습니다.
rook-cepht-block를 확인해 보면 allowVolumeExtension이 true인 것을 확인할 수 있습니다.
$ kubectl get sc rook-ceph-block -o yaml
allowVolumeExpansion: true
apiVersion: storage.k8s.io/v1
kind: StorageClass
metadata:
annotations:
stroageclass.kubernetes.io/is-default-class: "true"
creationTimestamp: "2021-11-17T09:16:57Z"
name: rook-ceph-block
...
...그럼 PostgreSQL PV의 PVC를 수정해서 용량을 늘려봅니다.
20Gi로 Size를 늘렸습니다.
$ kubectl edit -n airflow pvc data-airflow-postgresql-0
...
spec:
accessModes:
- ReadWriteOnece
resources:
requests:
storage: 8Gi -> 20Gi수정한 다음 바로 반영이 되지 않고 FileSystemResizePeding 상태가 되었다가 반영이 됩니다.
20Gi로 늘리니 Scheduler restart 하면 정상화된 것을 확인할 수 있습니다.
DB Clean
하지만 해당 방식은 근본적인 해결방안이 아닙니다.
Airflow 사용한 2년 동안 PostgreSQL에 많은 데이터가 쌓였는데 한 번도 정리한 적이 없습니다.
Airflow는 Backend Database에
- Job
- task_fail, task_instance
- Dag, DagRun
- Log
- Variables
- Celery 정보
등 다양한 데이터를 저장합니다.
History성 데이터들이 많이 저장되는데 해당 데이터들은 계속 가지고 있을 필요가 없습니다.
유지보수성으로 Rule을 정해서 최근 데이터만 유지하고 있으면 됩니다.
Airflow에서는 다행히 해당 기능을 제공해 주는 db clean입니다.
db clean command
Airflow db command는 Airflow 세팅 시 Backend DB에 실행할 때 이후로는 처음 보게 되었습니다.
db init을 통해서 Backend DB에 Airflow Table 등을 생성합니다.
이번에 살펴볼 command는 db clean입니다.
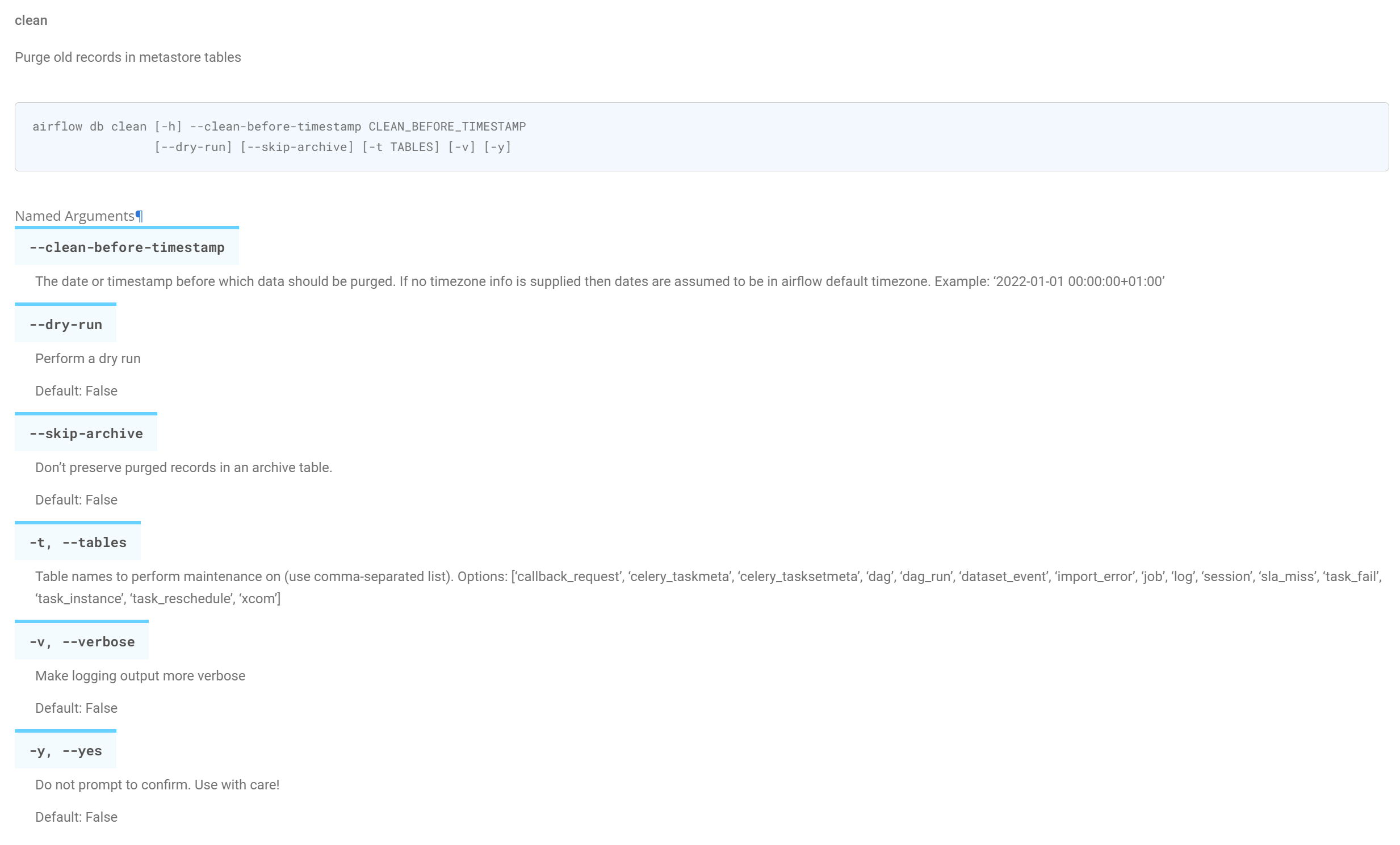
clean command로 Backend DB에 있는 History성 데이터를 정리해 줍니다.
clean-before-timestamp 옵션에 timestamp값을 넣어주면 해당 timestamp 이전 데이터를 삭제해 줍니다.
전체 말고 Table를 지정해서 일부만 삭제 가능합니다.
따로 지정하지 않으면 아래 Table의 데이터가 정리됩니다.(2023/09/20V.2.7.1 기준)
- callback_request, celery_taskmeta, celery_tasksetmeta
- dag, dag_run
- dataset_event, import_error, job, log, session, sla_miss
- task_fail, task_instance, task_reschedule
- xcom
$ airflow db clean --clean-before-timestamp '2023-09-20 00:00:00'
# table option
$ airflow db clean --clean-before-timestamp '2023-09-20 00:00:00' --tables 'xcom, log, task_instance'db clean로 주기적으로 데이터를 정리해 주면 No Space 에러는 나지 않을 것입니다.
또 다른 문제가 있었습니다.
cleanup table 생성
지금 사용하고 있는 Airflow 버전은 2.1.4입니다.
2.1.4에서는 db clean를 제공하지 않습니다.
당장 버전 업그레이드는 힘든 상황이라 직접 정리를 해줘야 했습니다.
정리해줘야 할 Table과 기준으로 정할 timestamp 칼럼을 찾기 위해 소스코드를 확인하였습니다.
Airflow db_clean.py에서 확인할 수 있었습니다.
run_cleaup () -> _cleanup_table()로 수행되는 것을 확인할 수 있습니다.
@provide_session
def run_cleanup(
*,
clean_before_timestamp: DateTime,
table_names: list[str] | None = None,
dry_run: bool = False,
verbose: bool = False,
confirm: bool = True,
skip_archive: bool = False,
session: Session = NEW_SESSION,
):
"""
Purges old records in airflow metadata database.
The last non-externally-triggered dag run will always be kept in order to ensure
continuity of scheduled dag runs.
Where there are foreign key relationships, deletes will cascade, so that for
example if you clean up old dag runs, the associated task instances will
be deleted.
:param clean_before_timestamp: The timestamp before which data should be purged
:param table_names: Optional. List of table names to perform maintenance on. If list not provided,
will perform maintenance on all tables.
:param dry_run: If true, print rows meeting deletion criteria
:param verbose: If true, may provide more detailed output.
:param confirm: Require user input to confirm before processing deletions.
:param skip_archive: Set to True if you don't want the purged rows preservied in an archive table.
:param session: Session representing connection to the metadata database.
"""
clean_before_timestamp = timezone.coerce_datetime(clean_before_timestamp)
effective_table_names, effective_config_dict = _effective_table_names(table_names=table_names)
if dry_run:
print("Performing dry run for db cleanup.")
print(
f"Data prior to {clean_before_timestamp} would be purged "
f"from tables {effective_table_names} with the following config:\n"
)
_print_config(configs=effective_config_dict)
if not dry_run and confirm:
_confirm_delete(date=clean_before_timestamp, tables=sorted(effective_table_names))
existing_tables = reflect_tables(tables=None, session=session).tables
for table_name, table_config in effective_config_dict.items():
if table_name in existing_tables:
with _suppress_with_logging(table_name, session):
_cleanup_table(
clean_before_timestamp=clean_before_timestamp,
dry_run=dry_run,
verbose=verbose,
**table_config.__dict__,
skip_archive=skip_archive,
session=session,
)
session.commit()
else:
logger.warning("Table %s not found. Skipping.", table_name)위 소스에서 _effective_table_names로 table 리스트를 가져옵니다.
table 옵션을 따로 안 주면 아래 config_list에서 가져오는 것을 알 수 있습니다.
config_list: list[_TableConfig] = [
_TableConfig(table_name="job", recency_column_name="latest_heartbeat"),
_TableConfig(table_name="dag", recency_column_name="last_parsed_time"),
_TableConfig(
table_name="dag_run",
recency_column_name="start_date",
extra_columns=["dag_id", "external_trigger"],
keep_last=True,
keep_last_filters=[column("external_trigger") == false()],
keep_last_group_by=["dag_id"],
),
_TableConfig(table_name="dataset_event", recency_column_name="timestamp"),
_TableConfig(table_name="import_error", recency_column_name="timestamp"),
_TableConfig(table_name="log", recency_column_name="dttm"),
_TableConfig(table_name="sla_miss", recency_column_name="timestamp"),
_TableConfig(table_name="task_fail", recency_column_name="start_date"),
_TableConfig(table_name="task_instance", recency_column_name="start_date"),
_TableConfig(table_name="task_reschedule", recency_column_name="start_date"),
_TableConfig(table_name="xcom", recency_column_name="timestamp"),
_TableConfig(table_name="callback_request", recency_column_name="created_at"),
_TableConfig(table_name="celery_taskmeta", recency_column_name="date_done"),
_TableConfig(table_name="celery_tasksetmeta", recency_column_name="date_done"),
]보면 Table 리스트와 기준이 될 column명 정리가 되어 있습니다.
해당 정보를 참고로 하여 delete문을 작성해 보았습니다.
저는 최근 3개월 데이터만 저장하고 나머지는 정리하는 방안으로 Rule을 정했습니다.
PostgreSQL이기 때문에 INTERVAL 함수를 통해서 쉽게 DELETE문을 만들 수 있었습니다.
해당 DELETE문으로 주기적으로 Airflow Backend DB를 정리하려고 합니다.
# python으로 delete 문 만들기
tbl_list = [
{'table_name':'job', recency_column:'latest_heartbeat'},
{'table_name':'log', recency_column:'dttm'},
...
...
{'table_name':'xcom', recency_column:'timestamp'}
]
for tbl in tbl_list :
table_name = tbl['table_name']
recency_column = tbl['recency_column']
print(f"DELETE FROM {table_name} WHERE {recency_column} < now() - INTERVAL '3 month';")celery_executor를 안 써서 그런지 아래 3가지 테이블은 없었습니다.
- callback_request
- celery_taskmeta
- celery_tasksetmeta
정리
이번 Airflow 이슈를 통해서 Airflow Backend DB에 대해서 자세히 볼 수 있는 계기가 되었습니다.
Airflow 소스코드를 살펴보는 것도 좋은 경험이었습니다.
그리고 버전의 중요성도 알게 되었습니다.
[참고사이트]
airflow 1.10.0 · apache-airflow/apache-airflow
The official Helm chart to deploy Apache Airflow, a platform to programmatically author, schedule, and monitor workflows
artifacthub.io
postgresql 12.11.2 · bitnami/bitnami
PostgreSQL (Postgres) is an open source object-relational database known for reliability and data integrity. ACID-compliant, it supports foreign keys, joins, views, triggers and stored procedures.
artifacthub.io
Resizing Persistent Volumes using Kubernetes
Author: Hemant Kumar (Red Hat) Editor’s note: this post is part of a series of in-depth articles on what’s new in Kubernetes 1.11 In Kubernetes v1.11 the persistent volume expansion feature is being promoted to beta. This feature allows users to easily
kubernetes.io
Command Line Interface and Environment Variables Reference — Airflow Documentation
airflow.apache.org
'Infra > Airflow' 카테고리의 다른 글
| Airflow Variables 세팅 - 전역변수 설정 (0) | 2023.07.23 |
|---|---|
| Kubernetes환경에서 Airflow를?!?! (0) | 2023.06.28 |
| How Airflow works? (0) | 2022.03.24 |
| What is Airflow? (0) | 2022.03.23 |



