
| 일 | 월 | 화 | 수 | 목 | 금 | 토 |
|---|---|---|---|---|---|---|
| 1 | ||||||
| 2 | 3 | 4 | 5 | 6 | 7 | 8 |
| 9 | 10 | 11 | 12 | 13 | 14 | 15 |
| 16 | 17 | 18 | 19 | 20 | 21 | 22 |
| 23 | 24 | 25 | 26 | 27 | 28 | 29 |
| 30 |
Tags
- Kafka
- Vision
- Operating System
- AWS
- MAC address
- java
- log
- ip
- Network
- JavaScript
- kubeadm
- Spring
- CVAT
- aws s3
- OS
- tcp
- Python
- zookeeper
- kubectl
- grafana
- docker
- airflow
- Trino
- helm
- Packet
- jvm
- EC2
- CSV
- PostgreSQL
- kubernetes
Archives
- Today
- Total
JUST WRITE
What is MapReduce 본문

MapReduce
MapReduce는 Hadoop HDFS 내 Data를 사용하여 처리하는 Progarmming Model이다.
Hadoop내 분산처리 엔진 역할을 하는 중요한 Component이다.
MapReduce는 2004년 Google에서 발표한 논문에서 시작되었다.
Hadoop MapReduce는 이 논문을 바탕으로 구현한 Framework이다.
데이터 분산 처리에 적합하며 key-value 알고리즘이 핵심이다.
장단점
장점
- 단순하고 사용 편리
- 유연성 -> 특정 데이터 모델이나 스키마, 질의에 의존적이지 않음
- 저장 구조의 독립성
- 데이터 복제에 기반한 내구성과 재수행을 통한 내고장성 확보
- 높은 확장성
단점
- 고정된 단일 데이터 흐름
- 기존 DBMS보다 불편한 스키마 질의
- 단순한 스케줄링
- 작은 데이터 저장/처리에 적합하지 않음
- 개발도구의 불편함
- 기술지원 어려움
동작
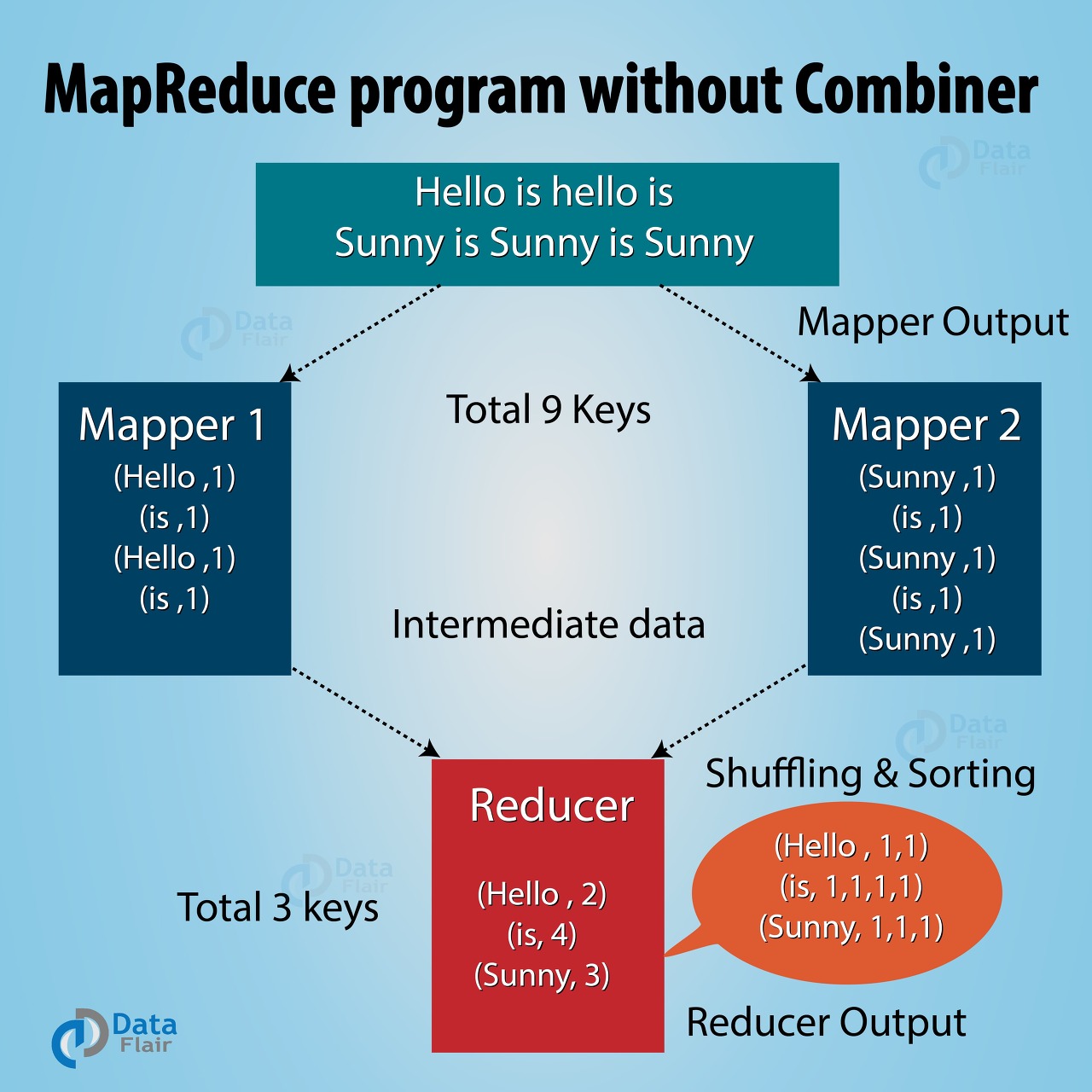
MapReduce는 크게 Map, Reduce 2가지 동작으로 나누어진다.
Map은 Data를 (Key, Value) 형태를 만들어 내는 동작이다.
Reduce는 만들어진 (Key, Value) 형태들을 같은 Key를 가진 값들끼리 합치는 동작이다.

- InputFormat
- InputFormat에서 물리적 Input 파일을 논리적 InputSplit으로 나눔
- InputSplit을 Mapper에 할당
- Mapper
- 비즈니스 로직이 들어간 첫 번째 데이터 처리 구간
- (Key-Value) 형태의 Partition정보가 있는 중간 결과 파일 생성
- Combiner
- Mapper를 수행한 Node 내에서 미리 Reduce 진행
- Data 전송량이 줄어들어 Traffic ↓
- Partitioner
- Data의 Key를 Hashing, Reducer 개수만큼 Moduler 연산
- Shuffling & Sort
- 같은 Key를 가진 중간 결과 파일을 논리적으로 같은 Server에 모음
- Reducing

728x90
반응형
'Data' 카테고리의 다른 글
| What is Nifi (0) | 2022.11.21 |
|---|---|
| What is MinIO? (0) | 2022.10.20 |
| What is YARN (0) | 2022.03.27 |
| What is HDFS (0) | 2022.03.25 |
| What is Grafana? (0) | 2022.02.23 |
'Data' Related Articles
more




Comments